




















Every business today has to deal with massive volumes of data, most of which is unstructured and locked in documents such as texts, email, PDF and scanned papers — which the traditional rules-based RPA technology is unable to process. Intelligent Document Processing (IDP) has been developed as a critical solution for large businesses, as RPA users have struggled to scale their document processing automation programs. Thanks to IDP cognitive capabilities, it is now possible to automate data capture, extraction and classification.
WorkFusion recently hosted an informative webinar on the opportunities and benefits of Intelligent Document Processing — featuring Anil Vijayan of Everest Group and Arnesh Sahay, a Machine Learning Engineer for WorkFusion, and moderated by Veronika Andreeva, Product Marketing Manager for WorkFusion.
More than 300 people have attended the free webinar so far, and it’s still available on demand. The 30-minute presentation was followed by a Q&A, and many attendees had additional questions about WorkFusion’s document processing solutions that we wanted to answer with some detail here.
Scroll for the answers to these topics:
- How are ML/NLP algorithms utilized in WorkFusion’s IDP solution?
- What does the initial training for a WorkFusion ML model look like? After an initial model is trained, how does the document processing software perform quality control against the model’s output?
- How does WorkFusion’s IDP solution solve for high volumes of data?
- Can IDP be used to read data from emails? Can we schedule bots to run at varying times for different processes?
- What does a false positive mean in the context of machine learning processes?
How are ML/NLP algorithms utilized in WorkFusion’s IDP solution?
WorkFusion Process AutoML is a proprietary technology for Cognitive Automation. AutoML automatically finds the best machine learning algorithm and method of document processing automation for myriad use cases. There are several different open-source algorithms leveraged in this process, depending on the type of model being trained.
In machine learning, a hyperparameter can consist of annotators, feature extractors, and various post-processors that are used to control the learning process. In order to produce the highest-performing machine learning models for any given use case, WorkFusion Process AutoML performs a series of experiments to test different “optimal” hyperparameter configurations by systematically varying one or more components and examining its effects on the result. This process is called hyperparameter optimization.
The two most common use cases deployed in WorkFusion’s Intelligent Document Processing software include information extraction: gathering data from unstructured documents to enter it into systems; and classification: classifying documents, transactions and emails into workflows. AutoML enables operations teams to train their own machine learning models without the need for a data scientist. AutoML SDK goes further and allows Machine Learning Engineers (MLEs) to step in and extend machine learning models for any information extraction or classification use cases. This SDK consists of the following components, each responsible for a specific task in a pipeline:
Parser — remove HTML tags from documents, create an AutoML SDK Document
Annotator — split text into tokens, add boundary elements, add Named-Entity Recognition (NER)
Feature Extractors — analyze tokens in documents and create features
Algorithms — aggregate all field documents and feature extractors, provide a model and its statistics
Post-Processing — apply normalization logic and field grouping
Some examples of machine learning algorithms that are supported in the AutoML SDK product include Support-Vector Machines (SVM), Deep Neural Networks (DNN), Regression, etc.
What does the initial training for a WorkFusion ML model look like? After an initial model is trained, how does the document processing software perform quality control against the model’s output?
The amount of data needed in the first iteration of training for an ML model depends on the complexity of the use case. An efficient information extraction model for a Prescription Intake use case can be created with as few as 50 documents, whereas a complex multi-class classification model for an Email Intake use case may require more than 100 documents per category.
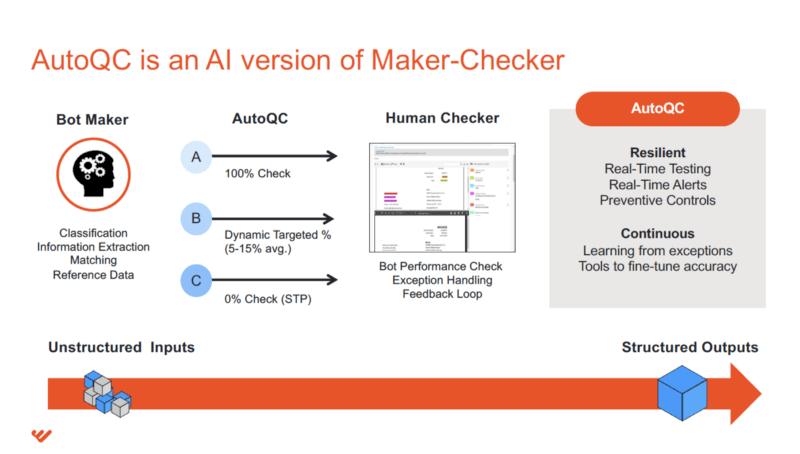
Automatic Quality Control (AutoQC) refers to the use of statistical methods in monitoring and maintaining the quality of products and services. In a WorkFusion automation workflow, the AutoQC sub-process chooses an optimal, cost-effective combination of automated machines and cloud workers that always delivers at or above the acceptable quality level.
The main concept of AutoQC is to take samples from a defined batch of items (records, documents, etc.) and verify the quality of each individual sample. After sample verification, the whole batch is considered as accepted or rejected depending on the Rejection Limit parameter set in the process. Therefore, AutoQC enables customers to automate and maintain a continuous quality check without needing to verify the entirety of the total batch.
Can IDP be used to read data from emails? Can we schedule bots to run at varying times for different processes?
Email Intake automation is a standard use case that WorkFusion has solved for several different customers. The data within emails (subject, body, attachments) are all parsed via RPA; any attachments are sent to the Optical Character Recognition (OCR) sub-process for conversion to a machine-readable format (XML/HTML); the body of the email is merged with the converted attachments; a single document is sent to the AutoML process. WorkFusion can tackle email intake process automation at large enterprises, involving massive email volumes and riddled with inefficiencies due to human error.
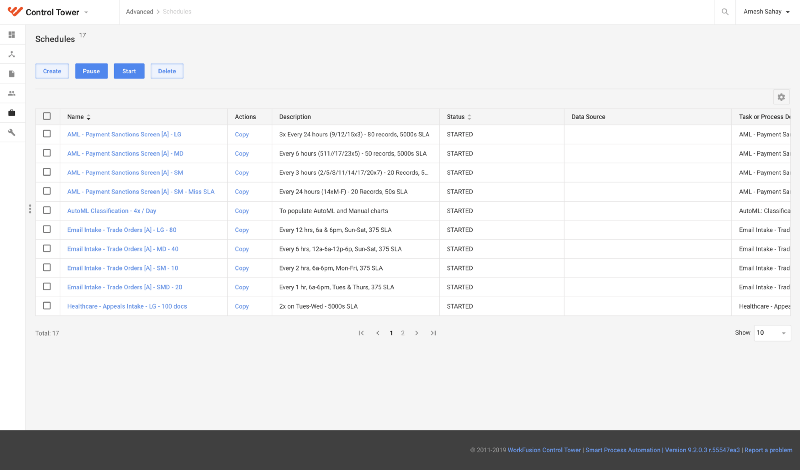
Scheduling bots is a simple and straightforward process in WorkFusion’s Control Tower. The image below shows how process owners can create their own schedules for various processes to kick off at designated times. This is a typical view in Control Tower:
What does a false positive mean in the context of machine learning processes?
When evaluating the performance of machine learning models, we need to be able to differentiate between values that were identified correctly and incorrectly. When looking at a Binary Classification use case, a correctly classified document can be either a True Positive (TP) or a True Negative (TN). Alternatively, an incorrectly classified document can be either a False Positive (FP) or a False Negative (FN).
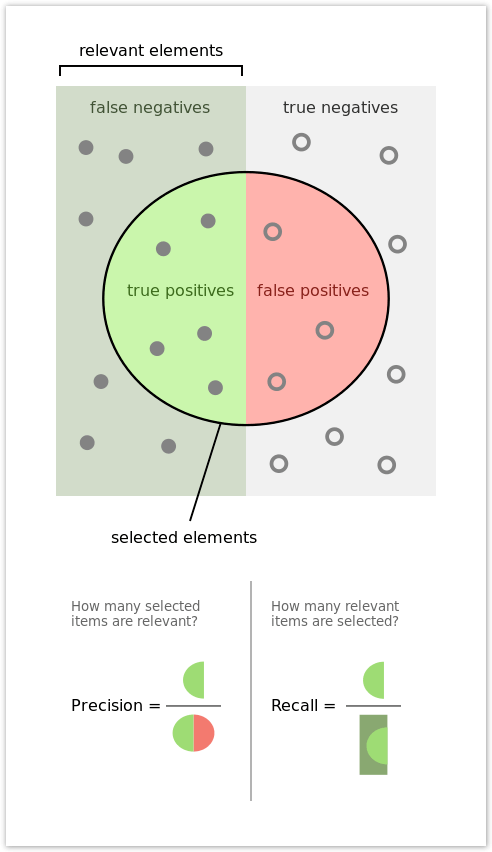
The definitions below pertain to a simple HotDog/NotHotDog use case, as presented on HBO’s “Silicon Valley” and help illustrate the differences between the four possible outcomes:
TP — Image is a hot dog and the model identified it as a hot dog. (Correct)
FN — Image is a hot dog, but the model identified it as not a hot dog. (Incorrect)
TN — Image is not a hot dog, and the model identified it as not a hot dog. (Correct)
FP — Image was not a hot dog, but the model identified it as a hot dog. (Incorrect)A binary classification model is relatively simple to calculate for. But when evaluating a more complex multi-class classification model, confusion matrices are often used to map out the four possible outcomes against each possible category, to better understand the performance of a model.
How does WorkFusion’s IDP solution solve for high volumes of data?
WorkFusion’s Enterprise Architecture is designed to handle high volumes of data coming in across multiple different business processes. To address the increased load on the systems, single instances can be scaled either horizontally or vertically. Horizontal scaling consists of provisioning more servers for ML, OCR, and RPA as needed to respond to increased volume growth, and vertical scaling refers to dedicating more powerful hardware to each component.
As different business lines within an organization start using WorkFusion’s Intelligent Document Processing solution, it is important to keep data segregated across different departments. There are two approaches to address this: One is to instantiate new environments that correspond to business units as they are onboarded and have sufficient volume (this is the most common approach); another is to set up a shared multi-tenant instance with scaled ML, OCR and RPA components.