
Our highly skilled and experienced AI Agents are AI AML analysts that enable your organization to quickly and easily scale your team to mitigate risk and improve program efficiency, freeing up time to focus on higher-value investigations and improving customer satisfaction.

Payment Sanction Screening Alert Review

Customer Identity Program (CIP) Doc Review

Customer Due Diligence (CDD) Doc Review

Email Triage and Coordination

Transaction Monitoring (TM) Alert Review

Perpetual KYC (pKYC) Refresh
Our highly skilled and experienced AI Agents are AI AML analysts that enable your organization to quickly and easily scale your team to mitigate risk and improve program efficiency, freeing up time to focus on higher-value investigations and improving customer satisfaction.
Payment Sanction Screening Alert Review
Customer Identity Program (CIP) Doc Review
Customer Due Diligence (CDD) Doc Review
Email Triage and Coordination
Transaction Monitoring (TM) Alert Review
Perpetual KYC (pKYC) Refresh
It normally takes several days or weeks for customer identity verification and validation during Customer onboarding and periodic refresh; however, Kendrick optimizes customer identity verification time and performs quality assurance reviews of identity documents and records for a much faster turnaround. He protects the organization’s reputation by verifying the identity of their customers in record time.
Kendrick automates the complete process, such as collecting, indexing, validating, extracting, and entering information into internal systems for customer onboarding or KYC onboarding and periodic refresh activities.
This section covers the following:
Prepare your Use Case (or Prepare your Digital Workers) dialog box is located under the Use Case/Digital Workers tab of Control Tower and then click on the settings button for the selected business process.
The document type selection allows users to configure distinct types of complex documents for storing, validating, extracting, and entering relevant data into the internal system.
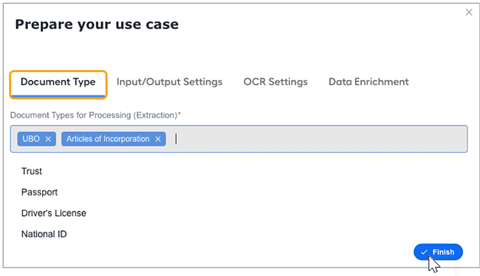
Kendrick processes the document types selected. If users are configuring Kendrick for the first time, this field will be empty, and users can select documents from the supported document types. Configuration includes allowing users to add or remove the document types
It enables the signature detection process of documents if it is required. Set up signature detection when required during the configuration process as outlined in the previous section.
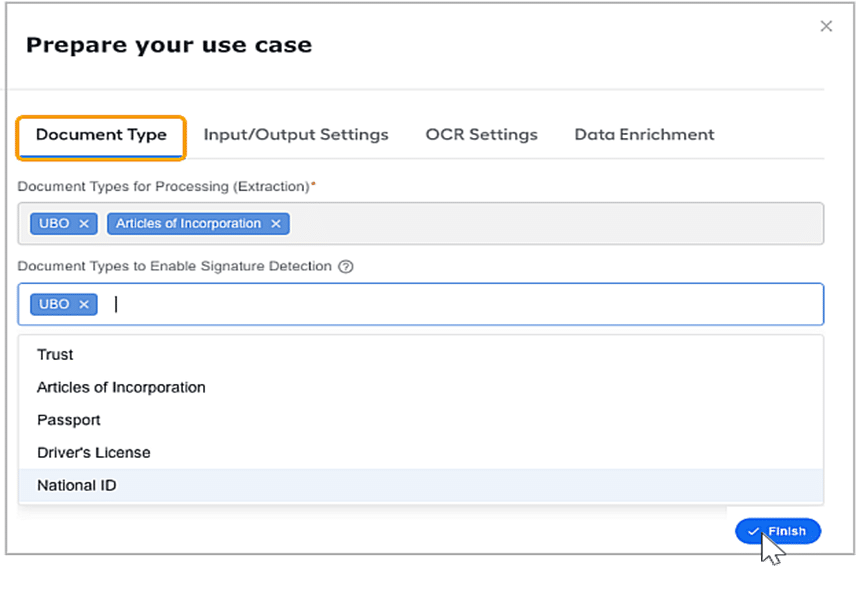
This section explains the ingestion process. There are two kinds of ingestion activities, general and document ingestion. It is located under the Use Case tab of Control Tower.
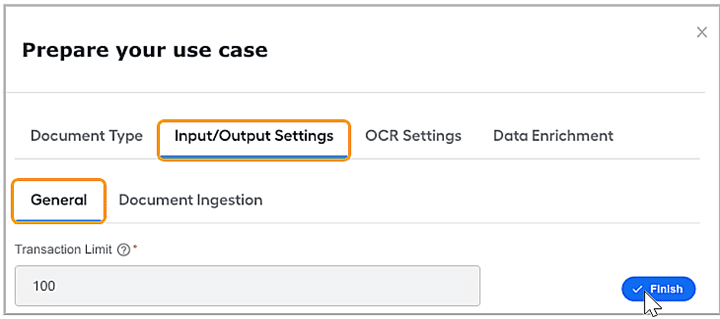
It determines the total number of transactions that can be processed in a single run; 150 is the recommended maximum. Under the Input/Output Settings, Document ingestion is the second option. The document handling digital worker supports the ingestion of documents via email and MinioS3 document storage.
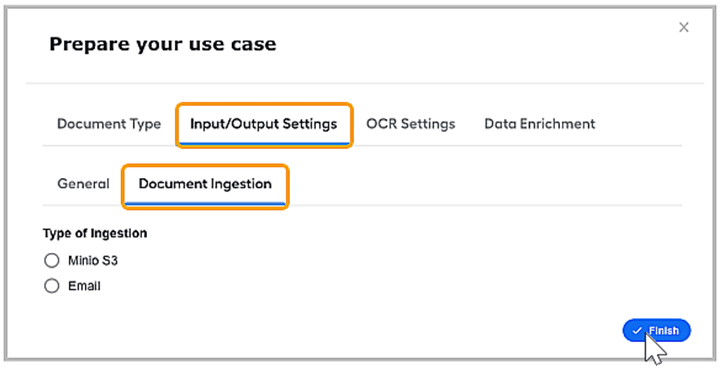
It allows the quick configuration of the folder in MinioS3 from where documents must be picked for processing.
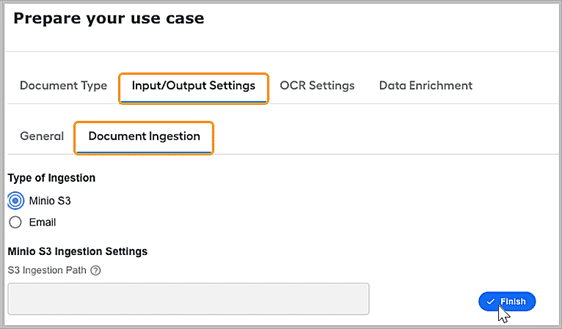
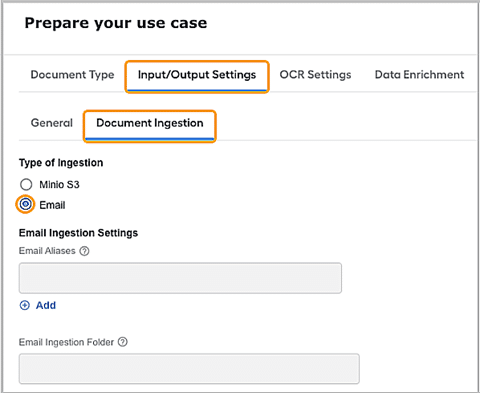
Email ingestion path has multiple options to configure for efficient document handling.
Email Aliases: Email credentials are stored in the Secrets Vault for security purposes and the aliases of those email inboxes can be configured.
Email Ingestion Folder: It is the S3 folder in which emails/attachments will be stored.
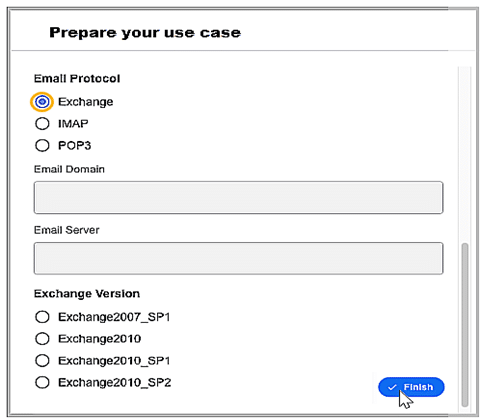
Kendrick allows the configuration of Email Protocol.
Parameter
Description
Email Protocol
Select the protocol with which the Exchange servers are connected.
Email Domain
This is for Exchange protocols. Domain of the email address.
Email Server
This is for Exchange protocols. Email server IP address.
Exchange Version
This is for Exchange protocols. Choose which version of your Exchange server must be supported.
Email Host
This is for IMAP and POP3 protocols. Specify the email host.
Email Host Port
This is for IMAP and POP3 protocols. Select the port used by the email host.
Email SSL Enabled
This is for IMAP and POP3 protocols. Enable or disable the email host’s SSL.
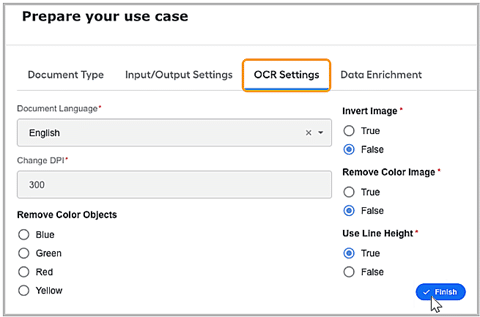
Allow configuration tuning for the OCR specification for Kendrick.
Kendrick provides the data enrichment URL unique for each client to provide maximum protection of confidential information. It helps apply configuration parameters and fetch data enrichment values.
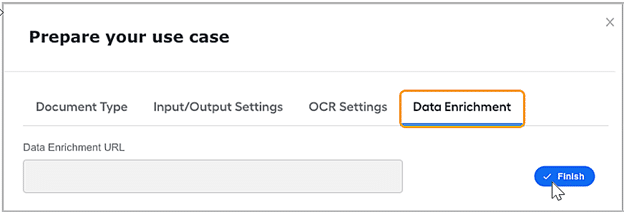
Kendrick supports different mediums of data submission.
Manually submitting data to Kendrick’s work environment as follows:
1. Ensure Kendrick’s configuration is set up to accept documents via Minio S3.
2. In the Minio UI browser, go to one of the following folders:
3. Upload files. The accepted formats are:
Note that individual files will be treated as a single transaction. Zipped files will be treated as a single transaction with multiple documents.
4. Files will automatically be moved into the “Processed-Documents” folder once the business process picks them up.
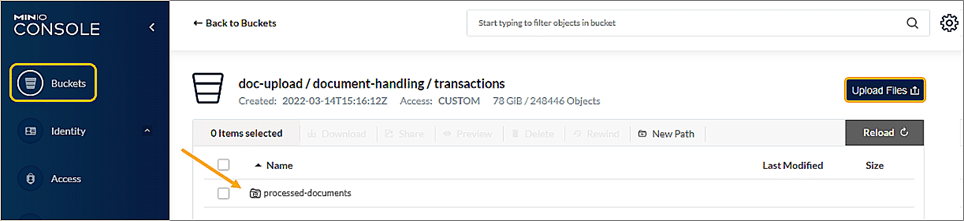
1. Ensure Kendrick’s configuration is set to accept documents via S3 Minio.
2. Select the Minio Doc Handling > Transactions folder.
3. Upload files. The accepted formats are:
a. PDF,
b. JPG, or PNG,
c. and zipped files.
Note that individual files will be treated as a single transaction. Zipped files will be treated as a single transaction with multiple documents.
1. Ensure Kendrick’s configuration is set to intake documents via email.
2. Emails should be sent to the specified email address with file attachments.
3. Upload files. The accepted formats are:
a. PDF,
b. JPG, or PNG,
c. and zipped files.
Note that individual files will be treated as a single transaction. Zipped files will be treated as a single transaction with multiple documents.
1. Under Control Tower menu, click Business Processes, click the name of the Ingestion Process to expand the process definition, and then click the process name. The BP window appears.
2. Click the three dots to expand a menu and make a copy of the business process.
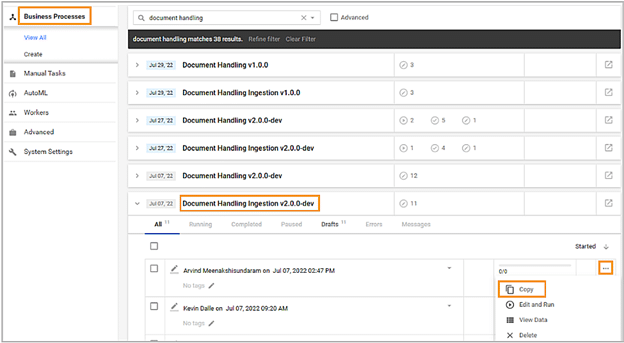
3. No data should be set in the data tab.
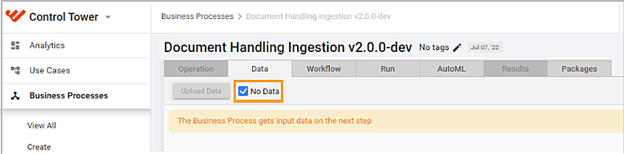
4. Save parameters, go to the Run tab, and click Run This Process.
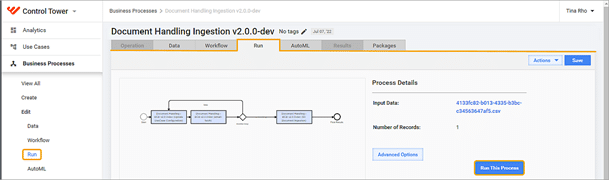
Now, wait for the Ingestion Process to complete.
5. Control Tower > Business Processes > Main Document Handling Process to expand the process definition.
6. Next, click the process name. The BP window appears. Follow the above 1 to 4 steps to run the second process.
Kendrick accelerates the process of Identity Verification by extracting pertinent data from documents, such as birth certificates, passports, and driver’s licenses, retrieving data from internal and external systems, and reconciling it all to uncover any discrepancies. The Identity Verification process is necessary due to KYC and AML regulations.
The Dashboard delivered with Identity Verification allows you to monitor and troubleshoot the underlying process, as well as evaluate its efficiency and quality through the key metrics such as Average Time to Verification, Automation Rate, Average Verifications Performed Daily and SLA. These metrics allow you to evaluate process throughput, understand high-level quality, monitor internal SLA, and predict impact on customer satisfaction.
Details on Country of Origin highlight lower-level issues with OCR when dealing with multiple languages, and Automation Rate by fields will indicate if there are any issues with specific area or type of document — for example, if templates are changing or there is a new type to deal with.

When working with Identity Verification and monitoring it daily, you may face some common scenarios. Below, you will find a description of how to find and address some of these typical situations with Analytics capability.
Problem: The processing of articles in languages that are not set in OCR violates SLA.
Description: Dealing with Identity Verification and document processing is a typical case: Various input document types originating from different regions and countries may come in different languages. To effectively process documents in different languages, the OCR component should be set accordingly and include appropriate languages.
From a process perspective, getting a document with a new unknown language will result in SLA violations since all those documents will require manual processing and validation, which will be seen in the SLA widget, highlighting in red cases outside of SLA. To double-check this hypothesis, we can check the Average Time to Verification widget. It should indicate an increase, and the trend line will indicate there has been a spike in the most recent days. At the same time, Volumes will not show any significant variance, meaning the incoming requests are coming at the same rate per day.
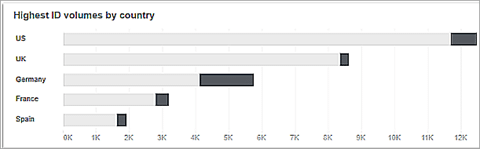
We may additionally limit the scope to the specified day and through the Highest ID Volumes by Country widget; we would see that Germany has mostly Failed to Parse statuses for documents — this will indicate issues related to a specific country and prove the initial hypothesis that there could be issues with country-specific document processing.
Solution: To resolve this case:
1. Modify the OCR setting and add the German language to the list.
2. Re-run the process.
3. Verify that processing in German ran successfully, and Manual Handling Time, along with SLA violations, returns to normal and expected values
Problem: Not all fields are recognized during data extraction.
Description: Data extraction is a crucial component of document processing. The issues at this step may result in different business impacts. This will cause increased Manual Handling Time, lower the process Throughput, and introduce compliance and customer satisfaction risks related to lower quality of work and increased time to process requests. As we can see, unexpected increases in processing time and SLA may be associated with a poor extraction quality, which will also decrease the Automation Rate. Still, due to high volumes of work, it may have gone unnoticed.

Solution: Checking the Automation Rate by Fields widget will indicate a poor quality on a specific field, and we can verify what type of documents it does relate to. Knowing the field name and type of document, we need to check the latest manual tasks and perform additional tagging to improve field recognition and data extraction processes.

Analytics evaluate process performance and find the bottlenecks. On a high level, general automation analytics relates to business impact, overall process performance, stability, accuracy, and quality.
The key metrics here are:
















