





















What are primary trends in the development of Intelligent Automation today?
Automation can be described through three stages: an early tactical period, the pandemic-driven automation phase, and the new direction toward the “automation fabric,” which supports the hybrid world of human and digital workers and offers unprecedented transformative opportunities. which supports the hybrid world of human and digital workers and offers unprecedented transformative opportunities.
The terms Intelligent Automation (IA) and hyperautomation caught on during the tactical period. The focus was fast deployment, clear ROI, and pragmatic AI support, such as text analytics for intelligent document extraction (IDE).
The pandemic then gave automation a booster shot, fueled by the need to conduct remote business and to support work remotely. Enterprises were pushed to rapidly automate and become savvy in process improvement platforms, methods, and service options. At the same time, physical worker shortages pushed investment in automation to support frontline service workers.
We are now entering the automation fabric phase, where companies realize that competitors that excel at automation will outperform them. They will see prior attempts in IA and hyperautomation fall short, despite being an accessible way to jump-start automation. Leaders will transform processes by weaving together automations in a thoughtful, scalable, and managed way. By 2024, this will include:
- A focus on AI-led process improvement. AI in various forms will find its way into almost every enterprise software category, including process improvement platforms. True transformation requires depth in machine learning, data integration, conversational intelligence, and process discovery.
- Data integration that addresses where automation is headed. A modern data integration strategy is essential to support the next generation of automation. Data virtualization, AI-enabled integration, and support for real-time data and modern edge applications become essential. Integration platform as a service (iPaaS), API management, extract, transform, load, and emerging data integration providers will become targets of process automation platforms. Why make a buyer choose between an API and robotic process automation (RPA) UI integration approach?
- Tools to integrate the physical and cognitive automation worlds. Stores, hotels, hospitals, warehouses, and restaurants report shortages for warehouse packing and sorting, delivery, food processing, and janitorial workers. These jobs become prime candidates for automation support but often operate on proprietary, disconnected technology stacks and are managed by specialized talent, both of which are isolated from the purview of automation centers of excellence. As robotics evolves and becomes mainstream, the automation must provide the connective tissue between the physical and the cognitive worlds.
- The merging of digital process automation (DPA) and low-code tools. Business developers will drive the democratization of automation, which will reach scale for many organizations in the automation fabric period. The low-code market disappears as declarative features are embedded in all automation tools and platforms to create more business-user-friendly, drag-and-drop development environments. As the automation fabric evolves, automation creation tools will become more refined and allow more flexibility within heterogeneous, bot-based, and API-based workflows.
Why is interest in IDE accelerating?
Wherever a document, form, email, or text — however simple or rich — enters a business process, there is a potential use case for IDE. They convey agreements, transmit information, notify parties, and bring order and structure to millions of transactions. Enterprises have been extracting fields from incoming content for decades, but AI in the form of natural language processing (NLP) and automation like RPA has accelerated IDE. Here’s why:
- Automation overall is paying off. Forty percent of business technology decision-makers reported using DPA or RPA platforms for process automation, where processes, especially in the case of RPA, are often document-heavy. According to Forrester’s Q1 2021 Robotic Process Automation Forrester Wave™ Customer Reference Survey, Forrester clients demonstrated increased ROI for enterprises investing in automation as high as 1.3 times for labor extraction and 0.9 times in improved process quality.
- Newer IDE solutions drive better extraction accuracy. IDE depends on NLP, the same technology that interprets words or text for chatbots. But IDE cares only about recognizing words such as names, places, invoice and account numbers, and other important fields in documents. It’s a form of machine learning in which basic statistics are used to estimate and project relationships among words. For example, NLP can count the number of name types used — like John, Jack, or John Smith — to determine the best name to use.
What are some of the top IDE use cases?
IDE use cases exist in almost every industry and for cross-industry applications as well, such as finance and accounting (see figure). Today, financial services and government dominate IDE use cases. This makes sense. At their core, these sectors manage information. For example, a midsize mortgage division used IDE to digitize over 1.8 million unstructured mortgage documents. Improved search-and-retrieve through autoanalysis, autoindexing, and autoclassification was the goal. Commercial insurance extracts needed data from workers’ compensation files, vehicle fleets, and building and property lists to prepare quotations. Insurance claims processing requires a slew of reports from doctors, test results, and even police reports. IDE can automate the reading of medical reports, treatment, and progress notes to accelerate the extraction of relevant data. Consumer credit needs identification (a driver’s license), address information, income (a payment slip), and bank account documents, which can have data with linguistic rules. Some IDE use cases just focus on data issues where sometimes proper routing of inbound content is all that is needed.
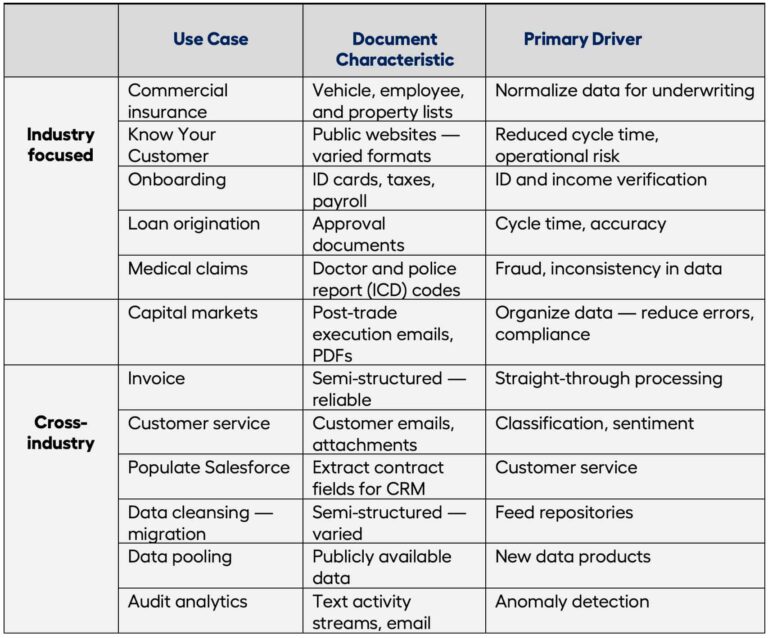
What are some lessons learned from recent IDE deployments?
IDE will continue to find new use cases as technology and experience expands. More complex extraction, insight, and action patterns will emerge. Extraction, insights, and action is a good way to think of the IDE process. It will align a solution with a business outcome and guide the business on what tool to use where. Once a clean data set is extracted, you can create the logic to meet your business objective. This insight will give you a sentiment score, a fraud warning, or show a “not in good order” error. Top lessons learned so far are:
- Classification is an important part of extraction in the process. Some IDE solutions classify a document based on a template alignment or text review as an early step. This allows the best extraction model to be applied. Wide variability of incoming documents benefits the most from early classification. Classification is also a form of insight, like a sentiment or fraud score, that can route an email or set of documents to the right workflow.
- The action component is often where the value is. So, now you have a clean set of structured data (essentially a document database) and know something about the character of each field. Next, you must develop logic to achieve your objective, such as determine sentiment, classify a document, compare fields for errors, or move a document to a queue for further processing. It’s best to use the provider’s expertise to get to the clean data set. Take over the insight and action steps. These are where your domain knowledge will shine.
- Human in the loop (HITL) is critically important. The best use cases had a strong HITL process that kicked in when unsure about an extraction. Humans via a crowd-sourcing approach, confidence-based routing, and in-process review were used. Remember: The goal is to get to that clean data set, the document database, and humans can help you do that.
- A quality audit process will address post-implementation concerns. When estimating IDE project ROI, be sure to include an audit process to assess the accuracy of your new solution. A simple comparison of human experts tagging and lifting fields compared with the automated system will suffice. If you have a legacy scan and Optical Character Recognition (OCR) system, for example, results can be compared with that.
- Do not go the “template” route. Modern NLP in IDE systems provides a “zoneless” extraction. This means that needed fields like “name,” “state,” and “address” can be found without being directed to a specific location. In older systems, a template would contain the specific rules to extract a field from its specific area or zone for a document. This newer agility is key to more accurate extraction but also easier system administration and enhancement.
- Linguistic interpretation is only one aspect of a clean data set. In most use cases reviewed, accuracy was augmented by reaching out to other systems. API links or RPA queries were often used to verify data from a core system or an address from an external public system. Traditional rules are also still viable. Be sure to allow for this additional work.
- Choose the platform that fits long-term needs. IDE involves advanced concepts like NLP, entity extraction, extraction models, and supervised learning, to name a few. Confusion in this area rivals that of more advanced AI systems, but it shouldn’t. Providers will use a combination of techniques. Business leaders can benefit from asking them which techniques they plan to use. Enterprises we spoke with had experience with several platforms. RPA suites, traditional capture solutions, dedicated text analytics platforms, cloud libraries, and tailored solutions from service providers were in the mix. They all have their place but recognize that: 1) IDE is an added layer to RPA and best for simpler use cases; 2) capture and OCR specialists are better at cursive handwriting and adjustments to incoming images; 3) specialized text analytics platforms have more NLP depth but may be short on the action or workflow component; and 4) consultant-led approaches are trending well as a managed service but may create support issues.
Watch this webinar on demand.
Interested in learning more about intelligent document processing, Digital Workers, and WorkFusion? Request a demo.